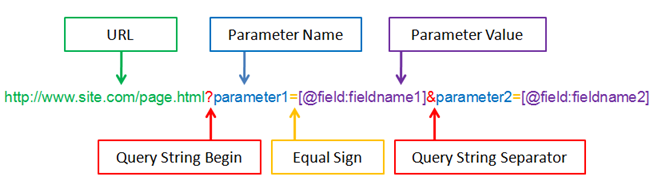
 Les paramètres d’URL situés après le « ? » et qui constituent la chaîne de paramètres (également appelée %{QUERY_STRING}) sont bien souvent source de duplication de contenu et d’URL inutiles crawlées par les robots d’indexation.
Les paramètres d’URL situés après le « ? » et qui constituent la chaîne de paramètres (également appelée %{QUERY_STRING}) sont bien souvent source de duplication de contenu et d’URL inutiles crawlées par les robots d’indexation.
Googlebot crawl parfois un grand nombre de ces URL qui dans certains cas ne sont que des paramètres de tracking. La combinaisons de plusieurs paramètres d’URL (et leur ordre) peut parfois amener à avoir une dizaine d’URL différente pour une seule et même page.
Afin de pouvoir identifier rapidement via les logs les différentes combinaisons de paramètres d’URL crawlées par Googlebot, nous avons avec Bertrand (enfin surtout lui en fait!) crée un petit script Shell qui a partir d’un fichier de logs (Apache par exemple) pourra extraire toutes les conbinaisons d’URL connues par Googlebot et le nombre de hits sur chacunes d’ente elles.
Cela peut être utile pour améliorer le crawl de Googlebot et mettre des restrictions dans le robots.txt ou faire le ménage lors d’une migration de site. (je ne crois pas trop au système de gestion des paramètres de Google Webmaster Tools, simple question de point de vue)
Fonctionnement
Avec un fichier d’un mois de logs d’un site Web, voici ce que le script vous ressortira:
Nombre de hits;paramètres dans les URL
38435;utm_source;utm_medium
2345;idproduct;tracking
234;id;page;
12;phpsessionid
Ce qui correspond à
– 38435 hits sur des URL de type /url?utm_source=xxxxx&utm_medium=xxxxx
– 2345 hits sur des URL de type /url?idproduct=xxxxx&tracking=xxxxx
– 234 hits sur des URL de type /url?id=xxxxx&page=xxxxx
– 12hits sur des URL de type /url?phpsessionid=xxxxx
Pratique non? 🙂
Le script
Il est nécessaire d’avoir préalablement filtré vos logs pour n’avoir que les hits de Googlebot. Voici comment les filtrer auparavant:
#cat meslogs.log | grep "Googlebot" > fichierdelog.txt
ou encore
#cat meslogs.log | grep "66\.249\." | grep -v "Googlebot-Image" > fichierdelog.txt
pour un filtrage plus restrictif
Voici donc le script qui vous permettra d’identifier les différentes combinaisons de paramètres d’URL connus par GoogleBot:
#!/bin/sh
colonne=$2;
awk '{
split($'"$colonne"',tab,"?") ;
url = tab[1] ;
Query = tab[2] ;
chaine = "" ;
l=split(Query,tab2,"&") ;
for (i=1;i<=l;i++) {
n=split(tab2[i],tab3,"=") ;
for ( j=1;j<=n;j+=2 ) {
chaine=chaine";"tab3[j] ;
}
}
print chaine
}' $1 | sort | uniq -c | sort -r
Et voici donc la commande pour exécuter le script sous Linux/Unix:
./paramurl.sh fichierdelog.txt 2
–> Le premier paramètre correspond au nom du fichier.
–> Le second paramètre correspond au numéro de la colonne des URL dans le fichier de logs.
Enjoy et n’oublier pas de suivre l’ami Bertrand et son tout nouveau Tumblr dédié aux astuces Shell (awk, cut, sed & co): Tom et Awk
Merci pour ce script, un peu compliqué pour ma gouverne mais je vais me faire conseiller !
Merci pour le script. Tu as pu constater clairement que le système de gestion des paramètres de GWT ne fonctionnait pas parfaitement même en étant bien configuré ?
Bonjour Aymeric,
Merci pour ce post bien pratique pour l’analyse de crawl, bon , à la mise en oeuvre bof bof…ah ! ces sacrées commandes linux..pas simple, parler avec une console c’est un métier ..j’avoue même si le copier coller aide bien..
Bon week end..
Bonjour Aymeric,
Top ton script ! Merci !
et merci également pour les explications
u’re welcome Damien 😉
Merci pour le script, j’ai un problème je suis null en Linux donc je fait un copier/coller sans rien savoir de quoi s’agit il