
 Lorsque vous scrappez les pages de résultats de Google dans le but de trouver des cibles potentielles pour vos campagnes de netlinking, il ne ressort souvent que très peu d’URLs potables sur un grand nombre d’URLs récupérées.
Lorsque vous scrappez les pages de résultats de Google dans le but de trouver des cibles potentielles pour vos campagnes de netlinking, il ne ressort souvent que très peu d’URLs potables sur un grand nombre d’URLs récupérées.
Séprarer le bon grain de l’ivraie pour peu de rendement au final, les grosses moissons d’URL demandent des ressources et surtout des proxys pour eviter de tomber dans les captchas…
Avoir la réponse au bout de son nez
Bien souvent, après avoir scraper des milliers de pages de résultats avec variation de mots clés, et autres commandes site:.{fr|be|net|com}, je me retrouve avec des centaines d’URL des mêmes blogs, qui ne sont pas forcément de bons plans. En pendant que je scrape les URLs de ces blogs, c’est autant d’URL plus pertinentes que je ne récupère pas.
Comment faire pour ne scraper qu’une seule page de chaque site, pour avoir un maximum de targets potentielles?
La réponse était devant moi, depuis toujours, sans que je n’y prête jamais vraiment attention: Google Blogs!
Google Blogs Search
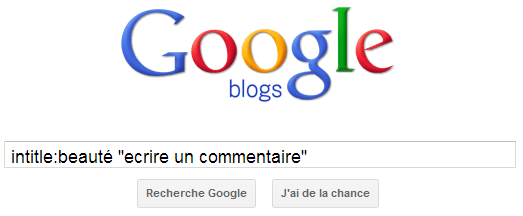
L’avantage de Google Blogs Search est que comme son nom l’indique, il filtre les résultats pour les sites ayant cette typologie, et permettant souvent de poster des commentaires intéressants liens optimisés.
Mais ce qui va nous intéresser, c’est la possibilité de n’afficher que les pages d’accueil de ces blogs et donc de récupérer un maximum d’URL différentes:
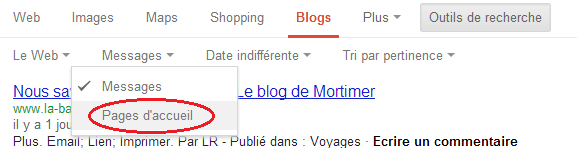
Voilà de quoi sortir une belle liste de sites Web en jouant avec les commandes inurl et intitle. Si vous n’avez pas utilisé de footprint spécifique pour détecter un CMS, vous pourrez toujours utiliser Whatweb pour connaître le CMS utilisé pour chacune de ces targets.
Paramètres pour le scraping
Si vous avez déjà votre propre script de scraping, voici les paramètres d’URL pour lancer la recherche sur Google Blogs:
– Google Blogs: Paramètre tbm avec la value blg
– Pages d’accueil seulement: Paramètre tbs avec la value blgt:b
ce qui donne https://www.google.fr/search?pws=0&tbm=blg&q=voyage&source=univ&tbs=blgt:b
Il ne vous reste plus qu’à configurer un nouveau profil de Scrap en Mode Expert dans votre RDDZ Scraper préféré !
Cette méthode de scrap vous permettra d’avoir pleins d’URLs en préservant un maximum vos proxys. Couplée à l’astuce de Watussi pour récupérer des NDD expirés et vous avez de quoi vous occuper pour cet hiver 😉


On oublie malheureusement trop souvent que Google nous fournit lui même tous les outils dont on a besoin…
Belle astuce.
Jolie moissonneuse !
Au passage, d’autres outils de Google mériteraient certainement d’y prêter attention. On peut facilement trouver des forums avec le moteur de recherche de discussions par exemple 😉
Aymeric, c’est tout simplement énorme comme astuce !
Sérieux, pourquoi on y a pas pensé avant ?!
J’entrevois déjà la syntaxe à changer sous RDDZ pour y arriver … A moins qu’une MAJ du scrapper soit déjà prévue ?! RDD ou DZ, si tu passes par là. 😛
Bref, merci beaucoup.
Sympa l’astuce, c’est vrai que scraper google blog est pas mal les targets changent et ça permet de diversifier un peu je trouve ^^
Et Merci Aymeric j’avais jamais capté qu’on pouvait procéder à un filtre « Page d’accueil » dans le recherche de blog de Google ! C’est vraiment de la balle !!! Par contre va falloir que je regarde comment implémenter ça dans scrapebox… Thanks
Très astucieux ! J’avais le même problème que toi, plusieurs sites nazes ressortaient quand je cherchais des BLs. Merci beaucoup, je vais tester ca tout de suite !
Excellente comme astuce. Avec RDDZ, une fois le scrap terminé tu peux supprimer les urls provenant du même domaine pour ne garder que l’url avec le PR le plus fort. Mais plus tu récupère d’url du même domaine, moins tu as des domaines différentes comme tu es limité à 1000 résultats par recherche. Je vais tester ton astuce avec RDDZ pour voir ce que cela donne.
Maintenant les problèmes sont que :
– tu ne sais pas combien de résultats donne ta requête (ce n’est pas affiché chez moi)
– tu dois trouver manuellement les bons articles à fort PR pour placer un lien (peut être que c’est une astuce que tu vas donner dans un prochain article ? :p)
Et bien une bonne astuce encore une fois !!
Jusqu’a présent pour récupérer la page d’accueil de mes résultats de scrap j’utilisais l’option de suppression « domain en double » dan RDDZ Scraper
Mais là ça va carrement plus vite 😉
Autre conseil que je donnerai pour certain bourrin : quand vous avez une liste d’url d’un blog à fort PR pas trop spammé ne garder qu’une seule url de se blog par session de spam comment.
Inutile d’aller spammé toutes les pages du blogs comme je vois parfois.
Oui magnifique. C’est dingue comme pris par les habitudes on en oublie à force d’utiliser des outils qu’on a sous les yeux.
Terrible. Merci
Très bonne idée !
Ca paraissait simple mais il fallait y penser, un outils de plus de Google qu’on n’avait sous les yeux mais dont on n’a pas réellement vu l’utilité ou du moins comment bien s’en servir.
En tout cas merci, je vais testé ça 🙂
Belle astuce effectivement. Une requête ciblée pour des résultats épurés. Je m’en vais tester RDDZ Scraper,j’utilisé ScrapeBox jusqu’à présent.
Super intéressant.
Vous utilisez quel outil pour la soumission ensuite ?
Imacros ou un script PHP, cela dépend des CMS utilisés.
Belle astuces carrément ;)… Et bon scrapebox c’est bien mais à la main ca se fait bien aussi, ou alors avec tes petites mains des philippines 😉
C’est énorme, j’ai envoyé un scrap ce matin et j’étais en train d’affiner certains résultats à la mano, mais je crois que mon RDDZ va être content (et moi aussi!) 😀
Royal, je relance un scrap de ce pas.
Merci beaucoup Aymeric pour cette astuce 😉
Excellente cette astuce. Pour le coup, je l’ai retweetée https://twitter.com/Netideal/status/291859676700766208
Merci Christophe 🙂
Nice Aymeric!
Merci, une belle astuce pour gagner du temps lors d’un scrap (car le temps c’est du proxy ne l’oublions pas).
Astuce, c’est le mot qui convient ! Moi qui commençait vraiment à trouver inefficace des outils comme Scrapebox, ce petit truc devrait vraiment beaucoup me plaire !!!
Toujours de bonnes astuces sur ce blog, je vais tester de suite 🙂
Mais c’est très bon ça ! Je déprime chaque fois que je crois avoir trouvé un filon, je scrape, et lors du trim to root je me retrouve avec seulement 20% des url, avec cette astuce je vais retrouver le sourire 😉
Gérard
Salut Aymeric et merci pour la mention.
C’est en effet une bonne trouvaille qui me rappelle fortement la galère que j’avais rencontré avec Scrapebox pour lui faire avaler le paramètre Verbatim (recherche mot à mot).
Pour les heureux possesseurs de RDDZ Scraper, vous trouverez sur le forum un export du moteur de recherche que tu proposes, prêt à l’emploi.
A bientôt mister (Dijon peut-être ?)
yes, à Dijon:) Bien vu pour l’export!
Sympa cette astuce, c’est vrai que cela permet de gagner pas mal de ressources que l’on peut utiliser à scrapper autre chose 😉
Merci pour l’astuce, j’ai trop pris l’habitude d’utiliser scrapebox et de délaisser des outils Google aussi simple que cela ! A+
Whoaw énorme l’astuce, je vais vite allez tester ça avec le RDDZ, ça fait quelques temps que je n’ai pas scrappé 😀
une astuce donnée au 1er barcamp black hat 🙂
ça m’apprendra, j’y étais pas ! j’ai toujours un train de retard moi…
L’astuce marche pas mal avec scrabebox ou il suffit de rentrer : google.fr+fr&tbs=lr_fr pour scraper les blogs.
Très bonne idée mais ces chers blogs ne vont pas être heureux d’être inondés de commentaires, grâce à toi !!
allé on met la page en favori pour pas oublier 😉
Excellent cette petite astuce et pourtant bien efficace.
Je vais peut etre me mettre a reutiliser SB pour scrapper .
Je reste un peu sur ma faim, c’est un outil que j’ai toujours utilisé, qui je pensais était utilisé par tous les SEO, mais apparemment non.. Dans mon utilisation je vois les choses de deux façons :
-> Récupérer les pages d’accueil : permet de trouver des blogs sur une thématique et de voir s’il y a des articles potables à commenter (mais prend plus de temps)
-> Récupérer les articles : pertinent pour récupérer des articles qui « remontent » bien dans les résultats (mais risque de se retrouver avec le même blog plein de fois)
Désolé de ne pas t’avoir donné assez à manger, apparemment je n’étais pas le seul 🙂
Ça reste quand même une bonne astuce qui méritait d’être partagée 😉 Dans certains cas ça reste quand même limité, notamment dans les domaines techniques (même si c’est moins le cas maintenant j’ai l’impression). Il y a quelques années pour des requêtes du type « pompe chaleur » (je n’ai plus l’expression exacte en tête) au bout de quelques pages les résultats étaient assez…particuliers 😉
Super découverte, en effet je n’ai jamais songé à tester des scraps sous GG blog search. Merci pour cette astuce qui fait gagner à priori beaucoup de temps pour une première sélection de blogs. Car ensuite une recherche de billets thématiques est utile.
Ça fait un moment que RDDZ scrapper me chatouille !
J’utilise tout le temps google blogs et c’est vrai que ça permet d’avoir de bons résultats.
Simple, efficace, merci beaucoup pour cette astuce, je vais tester de suite 🙂
Merci pour cette astuce !! C’est vrai que ça prend un temps de fou, voilà qui va me faciliter la vie 🙂
Merci pour cette astuce ,c’est là que nous voyons que le métier de référenceur demande et demandera toujours pour être bon, de la recherche, des idées et une petite pointe de génie !
SB vient d’être mis à jour et on peut désormais choisir blogsearch pour le scrape ^^ 🙂
Par contre je ne connaissais pas RDDZ, dis moi Aymeric tu pourrais peut-être nous faire un comparatif entre les deux soft? moi ça m’interesserai vachement
Merci pour cette astuce!
Si tu postes en masse avec IMacro sur du wordpress tu n’as pas peur de te faire topper par Askimet au niveau de ton IP?
J’utilise Elite Proxy Switcher:)
C’est pas gentil ^^
C’est dommage d’en parler en publique, fait longtemps que j’y utilisais et ça donne de bon spot.
Par contre j’y avais pas mis dans RDDZ, maintenant c’est fait. Merci.
J’utilise quick proxy mais c’est le même problème, si tu veux soumettre sur XX URLs avec iMacros, tu ne peux pas faire de random de proxys automatiquement, si?
Si!
HideMyAss est pas mal aussi :p
C’est avec des petites astuces que les petits peuvent être plus malins que les gros. Merci pour ce partage, pas mal le filtre page d’accueil, je connaissait pas… ils sont forts chez Google :)-
Merci pour cette astuce!
Parfois on cherche trop loin sa savoir que la réponse à notre question se trouve sous nos yeux!