Aymeric
Articles par Aymeric
Articles
Analyse des paramètres d’URL pour les audits SEO
Les paramètres d’URL sont souvent la source de problématiques SEO. Parmi les éléments les plus impactant pour le référencement naturel,…
Lire la suite
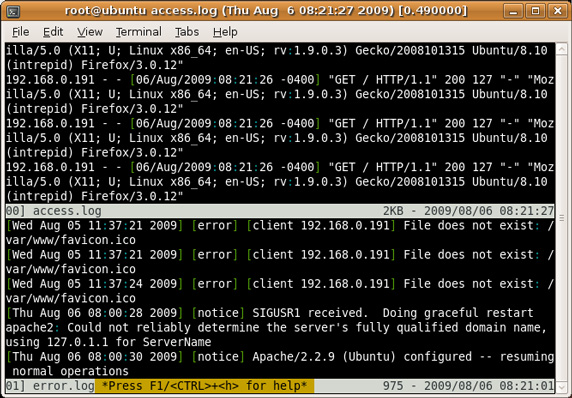
robots.txt et ordre de priorité des règles
Le fichier robots.txt qui permet de contrôler le crawl des moteurs de recherche nous réserve parfois des surprises (comme je…
Lire la suite
Slides SEOCamp 2021
A défaut de ne pas avoir mis à jour ce blog depuis plus de 5 ans, autant le réactiver pour…
Lire la suite
Les petites subtilités du fichier robots.txt qui peuvent faire mal
Le fichier robots.txt utile dans bien des cas, pour éviter des fuites de crawl (et contrôler au mieux la façon…
Lire la suite
La balise meta noindex et NSEO, attention!
Hier, j’ai vu passer un post de Gary Illyes (Webmaster Trends Analyst chez Google) qui m’a interpellé : https://plus.google.com/+GaryIllyes/posts/ZPPrxASiXf3 En effet,…
Lire la suite
Lazy loading d’ images et SEO sont sur un bateau
Pour ceux qui ne connaissent pas le Lazy loading, il s’agit d’une technique consistant à charger un objet sur une…
Lire la suite
Titre h1 de la home dupliqué sur toutes les pages d’un CMS
A plusieurs reprises, j’ai été confronté à un problème avec la balise <h1> en homepage des sites de mes clients.…
Lire la suite
Hangout Google et son update Mobile-friendly : ce qu’il faut retenir
Zineb Ait Bahajji (Google Zurich) et Vincent Courson (Google Dublin) de la Search Quality Team, ont répondu aux questions des…
Lire la suite