
Le fichier robots.txt qui permet de contrôler le crawl des moteurs de recherche nous réserve parfois des surprises (comme je l’avais évoqué dans un article précédent sur le comportement des crawlers par rapport aux directive User-agent)… On va voir ensemble une autre subtilité liée à l’ordre de priorité des règles.

Allow et Disallow, un bug?
Dans le cadre d’un audit SEO, mon outil de crawl préféré, alias Screaming Frog (question d’habitude, Seolyzer.io fait aussi des merveilles!) m’indiquait la présence d’URL bloquées dans le fichier robots.txt alors qu’il me semblait que ces dernières étaient autorisées au crawl…
Voici un extrait du contenu du fichier robots.txt en question :
User-agent: * Disallow: /wp-admin/ Disallow: /wp-includes/ Disallow: /wp-content/ Disallow: /wp/ Disallow: /*?* Allow: /*?s=* Allow: /*.js Allow: /*.css
Le crawl me remonte que cette url « wp-content/themes/noname/proto/build/assets/js/animations.js?ver=1626696210 » est bloquée par le fichier robots.txt.
Mais bon sang! pourquoi malgré la directive « Allow: /*.js », mon fichier « .js » n’est-il pas crawlé? Je vous vois venir, vous allez me dire que c’est à cause de la chaîne de paramètres en fin d’URL (?ver=…). Et bien non, car tant que la directive n’est pas fermé par un « $ », la règle tient compte de n’importe quel caractère après « .js »
Vérification de routine
Pour m’assurer qu’il ne s’agissait pas d’un bug avant de faire un petit mail à Dan Sharp et sa team Screaming Frog, j’ai préféré faire un test dans l’outil de test du fichier robots.txt de Google :
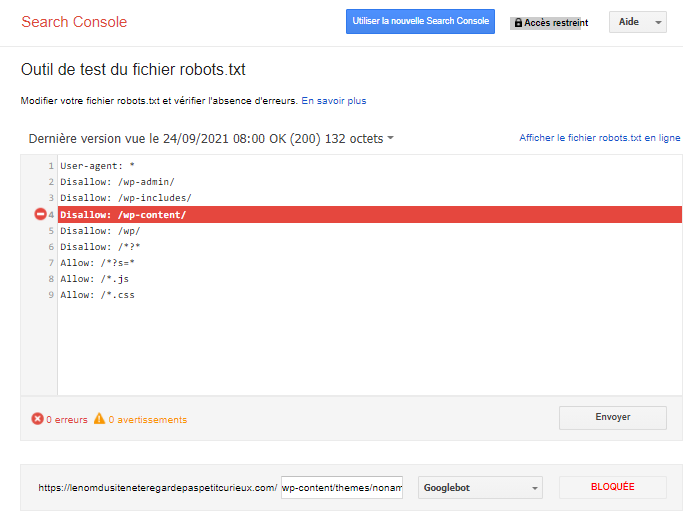
Le message est clair. Mon URL est bloquée… Ni une, ni deux, je file me replonger dans la documentation officielle de Google.
Ordre de priorité des règles : oui chef!
Et là je tombe sur une phrase on ne peut plus claire (malgré une traduction peut être pas optimale) :
Lors de la mise en correspondance des règles robots.txt avec les URL, les robots d’exploration utilisent la règle la plus spécifique en fonction de la longueur de son chemin.
La réponse est là. La directive « Disallow: /wp-content/ » est plus spécifique en fonction de la longueur de son chemin que ma règle large « /*.js », et c’est donc la règle qui prévaut. Pour permettre le crawl de mes fichiers JS et CSS liés à mon thème WordPress, il faut donc ajouter cette directive :
Allow: /wp-content/*.js Allow: /wp-content/*.css
Voici l’exemple que Google utilise pour illustrer ce comportement. Pour l’URL https://example.com/page.htm et les directives suivantes :
Allow: /page Disallow: /*.htm
L’URL https://example.com/page.htm ne sera pas crawlée. La règle applicable est « Disallow: /*.htm », car elle correspond à plus de caractères dans le chemin de l’URL de la directive. Elle est donc plus spécifique.
Et en cas de règles contradictoires?
Cette relecture de la documentation de Google m’a également rappelé un point important :
Dans le cas de règles contradictoires, y compris celles comportant des caractères génériques, Google utilise la règle la moins restrictive.
Concrètement ça veut dire que si on a les règles suivantes :
Allow: /folder Disallow: /folder
Pour l’URL https://example.com/folder/page, la règle applicable sera : « Allow: /folder », car dans le cas des règles contradictoires, Google utilise la règle la moins restrictive.
Pour conclure, soyez donc méfiants vis-à-vis des directives « Allow: » vs « Disallow: » qui ne font pas toujours ce que l’on pense qu’elles sont censées faire…!
Source : Comment Google interprète la spécification robots.txt, et le site de référence pour le fichier robots.txt : https://robots-txt.com/
PS : le SEOCamp’us Paris était vraiment cool, ça a fait plaisir de revoir tous les anciens copains SEO qui se reconnaitrons. ça m’a donné envie de me remettre à re-partager des tips. Yapasdequoi is back, mais jusqu’à quand… 😀



Merci Aymeric, ça fait plaisir de te lire à nouveau 🙂 !
hello
super article
mention spéciale pour l’outil de test du robots.txt dans la GSC, super utile dans les cas comme celui ci.
Et ça semble cohérent que Google prenne en compte la commande la plus proche de l’URL même si avec lui, il vaut toujours mieux aller regarder dans la documentation 🙂
Sympa de lire un nouvel article sur ce blog 🙂
Les règles de priorité du robots.txt est un sujet intéressant. Je m’amusais à l’évoquer en tests de recrutement. Personne n’avait la réponse mais les hypothèses du candidat montraient sa façon de réfléchir.
Il y avait un cas encore plus drôle, je découvre aujourd’hui en relisant la doc qu’il est désormais géré. Le cas où tu avais deux règles contradictoires dont une contenant un * était considéré par Google comme « undefined » (« The order of precedence for rules with wildcards is undefined. »).
Google lui-même ne savait pas ce qu’il allait faire ^^.
On peut retrouver la doc en question grâce à la wayback machine (https://web.archive.org/web/20160314181411/https://developers.google.com/webmasters/control-crawl-index/docs/robots_txt)
Je découvre ton blog. Merci pour ces explications claires sur les regles du fichier
robots.txt qui m’ont appris un truc !
avec plaisir Sandra!